Fuzzy Decision-making Process System for Improving CPU Scheduling Algorithm
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 3060 words | ✅ Published: 23 Sep 2019 |
CPU Scheduling
Abstract
Almost all computer resources are scheduled before use, and CPU is one of the most important and expensive resources in a computer system. Since the era of multiprogramming, an operating system allows more than one process/thread to be loaded into the main memory. CPU scheduling is a procedure in which an operating system selects a process out of a pool of ready processes to be given to the CPU for execution. In an operating system, the set of rules used to determine when and how to select a new process to be run on CPU is called its scheduling policy. The scheduling policies in most modern operating systems execute processes in a round robin fashion one after another either for a specific time quantum or until the process itself relinquishes the CPU.
In this paper, we present a new fuzzy decision-making process system aimed at improving CPU scheduling algorithm of a multitasking OS. The objective of the project was achieved by adding intelligence to the current scheduling algorithms through the integration of fuzzy methods in the selection of a process to be executed on CPU. The result of the project indicates improvement in waiting and turn-around times. The implementation of the proposed algorithm will be done using C language. The simulator tends to device an indistinct programming system and reads the indispensable organized constraints to effect progressions from a categorizer. Finally, it will figure out a dynamic priority (dpi) variable for each of the undertaken procedures. The study will add value to the inclusive determinations of the society by contributing to the fuzzification of different operational system units. The OS will effectively use the underlying hardware and software under accurate as well as uncertain conditions. The OS will present convenience to the users in both certain and uncertain surroundings.
Introduction/Background
An operating system (OS) is one of the most complex software built to manage the hardware, underneath a computer system. In a computer system, there are finite resources and competing demands. One of the main tasks that an OS performs is to allocate and deallocate resources among various processes competing for them in an orderly, fair, and secure manner. The most important hardware resource in a computer is the central processing unit (CPU) which is time multiplexed among multiple processes residing in the main memory. CPU scheduling is a procedure using which an OS selects a process out of a pool of ready processes to be given to the CPU for execution. A process/CPU scheduler is a kernel component that decides which process runs, when and for how long. Several pro-active as well as non-proactive CPU programming algorithms exist and are being utilized by the inclusive-drive operating systems such as the first in line will be the first to be served (FCFS), straight work first (SWF), straight residual periodic first (SRPF), priority-founded, rotund robin (RR), multi-level line programming, and a blend of such processes. CPU scheduling is a multiple-object decision-making process with multiple factors like CPU utilization, throughput, turn-around time, waiting time, and response time.
Literature Review
According to Ton-That, Cao and Choi (2014), the training data set and the method to form membership functions of a FIS (Fuzzy Inference System) definitely impact on its inferred results. So, collecting correct data set and method to form membership functions based on the collected training data are prerequisites to obtain desired results of a fuzzy inference system. This is one of the reasons why the data must meet specific criteria in making sure the data was specifically selected for solving a particular problem. The authors indicate that in fuzzy inference systems, the fuzzification of the OS inputs and defuzzification of the OS outputs are run by membership functions. Fuzzy rules execute the mapping from fuzzy inputs to fuzzy outputs.
Therefore, improvement of fuzzy inference systems can be done through two main aspects. These include developing the rule bases or advance in the membership functions. In first aspect, there are recently several proposed methods such as logic optimization, fuzzy linear optimization, upward search learning algorithm, genetic rule selection and lateral tuning, and learning error feedback (Ton-That, Cao and Choi, 2014).
According to Ajmani and Sethi (2013), fuzzy insinuation refers to the method of articulating the plan from a specified feedback to an outcome by means of ambiguous reasoning. Fuzzy inference systems (FIS) have been successfully applied in fields such as automatic control, data classification, decision analysis, expert systems, and computer vision system. The initial phase, fuzzification, commences by taking hard ideas and defines the magnitude at which such initial ideas fit into every applicable fuzzy arrangement. It is the mapping from universe of discourse to membership value. In the second step, the inference engine triggers the appropriate IF-THEN rules in the knowledge base using different inference methods like Mamdani, Larsen, Tsukamoto, and TSK (Ajmani and Sethi, 2013). Finally, in the third step, the aggregated output fuzzy set is defuzzified to achieve crisp output. Some of the commonly used defuzzification methods are centroid, weighted average, mean of maximum, center of largest area, maximum membership
Findings and Analysis
A computer system works on Boolean logic, in which the state of an entity/element may be ON or OFF, also referred to as true or false. However, in many scenarios, we cannot evaluate a situation to be completely true or completely false. Presently, science and technology are featured with complex processes and phenomena for which complete information is not always available. For such cases, mathematical models are developed to handle the type of systems containing elements of uncertainty. A large number of these models are based on an extension of the ordinary set theory, namely fuzzy set theory and fuzzy logic.

A lot of research has been carried out to implement fuzzy logic to schedule processes in a time-sharing system. Round robin is one of the most common CPU scheduling algorithms used in a time-sharing system. In this algorithm, each process executes for a specific time quantum on turnaround basis. Selection of this time quantum is an important design issue. A very large time quantum larger than the largest burst time of a process makes this algorithm equivalent to FCFS, thus increasing the average response time of a process. On the other hand, making it too short increases the number of context switches and, thus, reducing the throughput of the system.
Fuzzy sets and fuzzy logic have been applied by researchers in a variety of areas including medical and life sciences, management sciences, social sciences, engineering, statistics, graph theory, artificial intelligence, signal processing, multi-agent systems, pattern recognition, robotics, computer networks, expert systems, decision making, and automata theory. Fuzzy logic is used in the scenarios that involve inexact and fuzzy concepts. Fuzzy logic uses a fuzzy rule base to arrive at a decision involving vague input data. Early work in fuzzy decision making was motivated by a desire to mimic the control actions of an experienced human operator and to obtain smooth interpolation between discrete outputs that would normally be obtained.
Many fuzzy inference systems and defuzzification techniques have already been developed. These techniques are useful in obtaining crisp output from a fuzzy input. The crisp output values are calculated using fuzzy rules applied in an inference engine using defuzzification methods. Several fuzzy controllers have been developed using fuzzy logic and fuzzy set theory. Varshney et al. uses fuzzy logic to achieve a time quantum which is an average between these two extremes (Varshney, Akhtar and Siddiqui, 2012). Hamzeh proposes a fuzzy scheduling approach for multiprocessor systems.
Lim and Cho recommend a smart central processing unit course used to program an algorithm based on fuzzy reading with operator prototypes. They divide processes into three different flavors, namely real time, interactive, and batch based on their use of system calls and CPU ticks. Many researchers have introduced fuzzy inference systems based on different scheduling inputs like static priority, remaining burst time, waiting time, and response ratio of processes to compute their dynamic priority. Their work has shown improvements over the standard scheduling algorithms ensuring reduced average waiting time and average turn-around time.
Our research work is an extension of this work in which we have designed and analyzed a fuzzy decision-making system that is used to improve the CPU scheduling algorithm of a multitasking operating system. We have used a novel formula for computing the recent CPU usage of every process. Moreover, our algorithm caters for the time slices and recomputes the dynamic priority of processes on arrival of a high-priority process and on expiration of a process’s allocated time quantum. A simulator will be written in C that reads a file to take each ready process’s burst time, nice value, and arrival time as input. It will later compute the recent CPU usage of each process using a formula.
The three parameters burst time, nice value, and recent CPU usage are fuzzified and given as input to our inference engine, which is composed of twenty-seven fuzzy logic rules. Based on these fuzzified inputs, the inference engine triggers appropriate fuzzy rules to generate fuzzy dynamic priority (dpi) for each process. This dpi is recalculated every time a context switch occurs. This fuzzy dpi value of each process is then defuzzified using centroid defuzzification method. In conclusion, the route column is arranged based on the dpi of all procedures in a downward sequence and the developments at the top of the line are chosen to run on the central processing unit.
Results
The switching of the CPU from one process to another is known as context switch. In SCHED_RR scheduling policy, the selected process executes for a specific time quantum which is a numeric value that represents how long a process can run until it is preempted. Burst time is the amount of time that a process wants to execute before it generates an I/O request or terminates. Arrival time is the time at which a process enters in the system. Recent CPU usage is the percentage of the amount of time that a process has used CPU. Every process has an associated attribute that is called its nice value. A process can increase/decrease its nice value in order to decrease/increase its priority, respectively. Waiting time is the amount of time a process has spent waiting inside the ready queue and is computed as ‘‘finish time arrival time executed time’’. Turn-around time is the amount of time a process has spent inside the system and is computed as ‘‘finish time arrival time’’.
To generate the results, we will use the Process Scheduling Simulation, Analyzer and Visualization (PSSAV) tool for simulation of round robin algorithm for different time quantum ranging from 2 to 6 ms. The PSSAV is publically available under code license GNU GPL v2. To generate the results for our novel fuzzy decision-making system for CPU scheduling algorithm, we write our own simulator in C language.
The basic structure of our proposed fuzzy decision-making system for CPU scheduler is shown in Figure 1. It is a three-input and one-output fuzzy inference system. The three inputs are the burst time, nice value and recent CPU usage of all the processes in run queue. The two attributes, namely burst time and nice value, are read from an input file, while the third attribute, recent CPU usage, is calculated using the formula mentioned below. The three input parameters are fuzzified and then passed to the fuzzy inference engine comprised of twenty-seven fuzzy rules. The output of the fuzzy inference engine is later defuzzified to a crisp value which is the dynamic priority of the processes.
Recent CPU usage of process Pi =
In this formula, CT is the current time; AT is the arrival time of Pi, ET is the executed time of Pi; TBT is the total burst time of all processes.
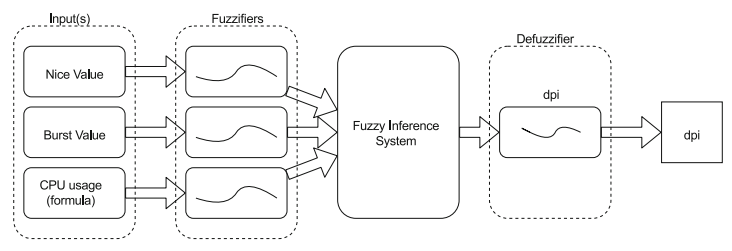
Figure 1: The fuzzy decision-making system for CPU scheduler
The flowchart of the proposed algorithm will look as indicated in Figure 2. The figure shows different steps of our proposed algorithm. It begins by reading a text file containing the count of processes, their arrival, and burst times. It then initializes the process control block (PCB) structure of all the processes. The recent CPU usage of every process is also computed using the formula indicated above.
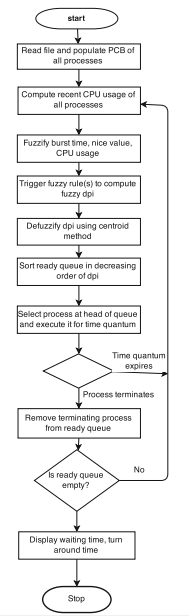
Figure 2: Flowchart of the fuzzy scheduler
The three input attributes of every process (i.e., arrival time, burst time, and recent CPU usage) are fuzzified using the triangular membership functions. These three fuzzy inputs are then given to the inference engine. After triggering the rules, it generates dynamic priority (dpi) for each process. Every process’s dpi is then defuzzified using centroid method. The processes are then placed in a queue in decreasing order of their crisp dpi. The process at the head of the queue (highest dpi runnable process) is selected for execution on CPU for a specific time quantum. If the time quantum for that process expires, the recent CPU usage and in turn the dpi for that process are recomputed and it is placed in the queue at appropriate place (de Oliveira et al., 2016). If the process terminates, it is removed from the run queue and another process from the head of the run queue (highest dpi runnable process) is selected to execute on the CPU for time quantum. This procedure is continued until the run queue goes empty. Finally, the waiting time and turn-around time of every process and the entire system are calculated.
The algorithm for the steps is as below.
1. Begin
2. FIS = create fuzzy inference system
3. Define linguistic values of input variables; burst time, nice value, and CPU usage
4. Define linguistic values of output variable: dynamic priority
5. Read input file and initialize PCB of each process
6. Compute recent CPU usage
7. Fuzzify the three input parameters
8. Trigger fuzzy rule base and compute dpi of each process
9. Defuzzify each process’s dpi
10. Sort run queue in decreasing order of process’s dpi
11. Select the process at the head of the queue for execution
12. If process terminates; remove it from run queue and go to step 11
13. If time quantum expires or a high-priority process arrives; go to step 6
14. End
Related Work
In cloud computing, virtualization technology is employed to achieve scalability. Virtualization regards the process of the creation of virtual machines over underlying hardware that mimics a real system (Moharana et al., 2018). Virtual machine monitors (VMMs) such as Xen and Vmware are the fundamental environments for the virtualization of physical systems into virtual systems. Additionally, there is increasing need for suitable virtual management. This not only maximizes the use of resources but also the minimization of physical infrastructure.
In virtualization, numerous guest OS (guest domains) operate on top of the virtual machine manager. The guest OS can be viewed as virtual representations of actual machines with the virtual resources to be considered operational. The key resources in virtual machines are virtual CPUs and virtual memory. The virtual CPU attached to that OS facilitates the CPU requirements of the virtual domains. The virtual CPUs are mapped to actual CPUs. They are allowed to consume CPU time from the actual CPUs. Typically, the virtual CPUs are more than the actual CPUs. Therefore, the allocation of the actual CPUs to the virtual CPUs is overwhelming for VMMs. The mapping of the virtual CPUs to actual CPUs is the CPU scheduling within virtual machine monitors.
For effective mapping of the virtual CPUs, scheduling techniques employed must efficient usage of the entire system. This is achieved by balancing the load among all the CPUs. The CPU scheduling technique involves pinning the virtual CPUs to every active domain. The actual CPUs are also pinned to the virtual CPUs. In their project, Moharana et al (2018) designed a CPU scheduling technique that culminated in the utilization of both actual CPUs and virtual CPUs.
Conclusion
Today, there is a dire need that operating system researchers seriously work in finding out places where decision making is done under vague and imprecise conditions in operating system code. Fuzzification of different operating system modules is an emerging field of computational intelligence. Fuzzy modeling techniques are used to improve the existing decision-making algorithms for achieving performance gains as well as enhancing the user-friendliness of an operating system. We have presented a novel fuzzy decision-making system to improve CPU scheduling algorithm of a multitasking operating system. The computation of recent CPU usage of every process and using it in the inference process played the major role in improved waiting and turn-around time. The overall complexity of our algorithm is O(nlogn), where n is the number of processes involved in the selection at any instant of time.
Insight on future directions
We intend to successfully deliver the proposed fuzzy decision-making system for CPU scheduler alongside its algorithm. In the near future, we plan to extend our study by making our proposed algorithm intelligent enough to differentiate between batch, interactive, real time, CPU bound, and I/O bound processes. For example, by increasing the nice value of batch processes and decreasing the nice value of interactive processes by a specific threshold, the interactiveness of the system can be further improved. Similarly, this inference engine can also be converted into a soft or type-2 fuzzy system to cater for the uncertainty element. Efforts can also be made to add another decision-making submodule that can increase or decrease the time quantum given to a high- or low-priority process, respectively. This may further improve the overall performance of the system. Finally, a comparative study can be done between these systems.
References
Ajmani, P., & Sethi, M. (2013). Proposed fuzzy CPU scheduling algorithm (PFCS) for real time operating systems. BVICAM’s Int J Inf Technol 5, 583–588.
de Oliveira, L. et al. (2016). A fuzzy-swarm based approach for the coordination of unmanned aerial vehicles. Journal of Intelligent & Fuzzy Systems, 31(3), 1513–1520.
Khodr, H. M. (2012). Scheduling problems and solutions. New York: Nova Science Publishers, Inc.
Lim. S., & Cho, S. (2007). Intelligent OS process scheduling using fuzzy inference with user models. In: Okuno HG, Ali M (eds) IEA/AIE, pp 725–734.
Moharana, S.C. et al. (2018). Dynamic CPU scheduling for load balancing in virtualized environments. Turkish Journal of Electrical Engineering & Computer Sciences, 26, 2512-2524. doi:10.3906/elk-1709-112.
Varshney, P.K., Akhtar, N., & Siddiqui, M.F.H. (2012). Efficient CPU scheduling algorithm using fuzzy logic. Int Conf Comput Technol Sci, 47,:13–18.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal